

In this project we address joint object category, instance, and pose recognition in the context of rapid advances of RGB-D cameras that combine both visual and 3D shape information. RGB-D cameras are the underlying sensing technology behind Microsoft Kinect. The focus of this project is on detection and classification of objects in indoor scenes, such as in domestic environments.
Overview
Personal robotics is an exciting research frontier with a range of potential applications including domestic housekeeping, caring of the sick and the elderly, and office assistants for boosting work productivity. The ability to detect and identify objects in the environment is important if robots are to safely and effectively perform useful tasks in unstructured, dynamic environments such as our homes, offices and hospitals. In this project we address joint object category, instance, and pose recognition in the context of rapid advances of RGB-D cameras that combine both visual and 3D shape information. The focus is on detection and classification of objects in indoor scenes, such as in domestic environments. The ability to recognize objects at both levels is crucially important if we want to use such recognition systems in the context of specific tasks, such as human activity recognition or service robotics. For instance, identifying an object as a generic “coffee mug” or as “Amelia’s coffee mug” can lead to substantially different implications depending on the context of a task.
Detection-based Object Labeling in 3D Scenes
In this work we propose a view-based approach for labeling objects in 3D scenes reconstructed from RGB-D (color+depth) videos. We utilize sliding window detectors trained from object views to assign class probabilities to pixels in every RGB-D frame. These probabilities are projected into the reconstructed 3D scene and integrated using a voxel representation. We perform efficient inference on a Markov Random Field over the voxels, combining cues from view-based detection and 3D shape, to label the scene. Our detection-based approach produces accurate scene labeling on the RGB-D Scenes Dataset and improves the robustness of object detection. Watch the video below to see labeling one of the scenes in the RGB-D Scenes Dataset.Scalable Tree-based Approach for Joint Object and Pose Recognition
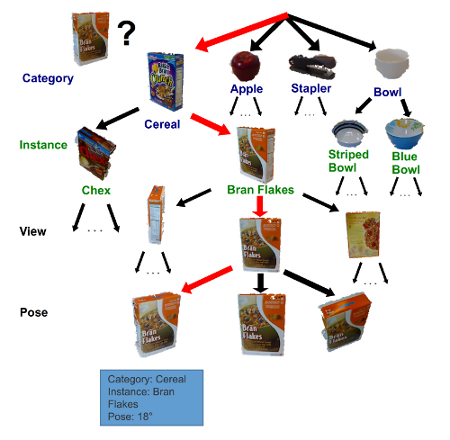
Recognizing possibly thousands of objects is a crucial capability for an autonomous agent to understand and interact with everyday environments. Practical object recognition comes in multiple forms: Is this a coffee mug? (category recognition). Is this Alice's coffee mug? (instance recognition). Is the mug with the handle facing left or right? (pose recognition). We present a scalable framework, Object-Pose Tree, which efficiently organizes data into a semantically structured tree. The tree structure enables both scalable training and testing, allowing us to solve recognition over thousands of object poses in near real-time. Moreover, by simultaneously optimizing all three tasks, our approach outperforms standard nearest neighbor and 1-vs-all classifications, with large improvements on pose recognition. We evaluate the proposed technique on a dataset of 300 household objects collected using a Kinect-style 3D camera. Experiments demonstrate that our system achieves robust and efficient object category, instance, and pose recognition on challenging everyday objects.
Application: OASIS (Object-Aware Situated Interactive System)
OASIS is a software architecture that enables the prototyping of applications that use RGB-D cameras and underlying computer vision algorithms to recognize and track objects and gestures, combined with interactive projection. The Object-Pose Tree described above forms the object recognition component of OASIS. The system recognizes objects that are placed within the interactive projection area so that the appropriate animations and augmented reality scenarios can be created. Our approach uses both depth and color information from the RGB-D camera to recognize different objects. Novel objects can be trained on the fly and recognized in the future.
One example OASIS application is the following interactive LEGO playing scenario that was shown at the Consumer Electronics Show (CES) 2011.
Leveraging Web Data for Object Recognition via Domain Adaptation
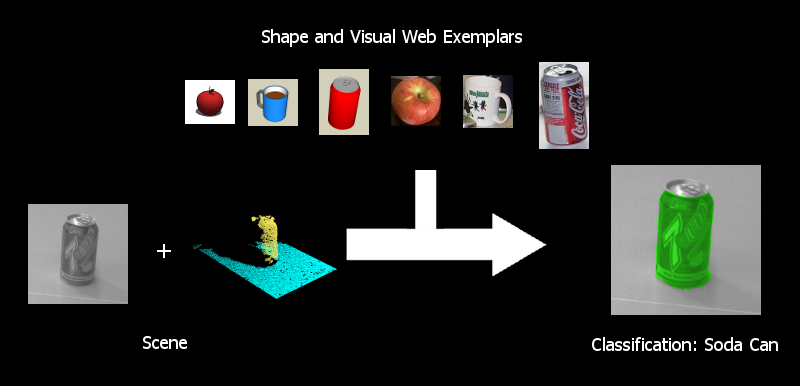
The ability to detect and identify objects in the environment is important if robots are to safely and effectively perform useful tasks in unstructured, dynamic environments such as our homes, offices and hospitals. One major obstacle to robust, many-class object recognition is the need for sufficient labeled training data to learn good classifiers. In this project, we investigate how to significantly reduce the need for manually labeled training data by leveraging data sets available on the World Wide Web. In contrast to much previous work on object recognition that have focused on one sensor modality such as vision, we investigate the use of multiple sensor modalities for object recognition. Specifically, we investigate techniques for combining visual information from camera images and shape information from a depth sensor (e.g. stereo or laser rangefinder) to do object recognition jointly in a single framework. We use images from LabelMe and 3D models from Google 3D Warehouseto train classifiers for realistic outdoor and indoor scenes encountered that may be encountered by a robot. In order to deal with the different characteristics of the web data and the real robot data, we additionally use a small set of labeled data collected by the robot and perform domain adaptation.
Indoor Multi-Sensor Classification
The image below shows the segmentation and classification results for three different objects: mug, book, and water bottle (top to bottom). Each column shows results when using (left to right) shape features only, visual features only, and combining both. Colors indicate the assigned object class (green: mug, brown: laptop, blue: book, red: apple, cyan: water bottle).

Outdoor Shape Classification
We investigated classifying 3D laser scans collected by a vehicle driving through an urban environment. In this work, we only used shape information. 3D models on Google 3D Warehouse served as our online source of training exemplars. Click on the images below to see an example. The image on the left is the classification attained by our technique. The one on the right is the ground truth. Cyan is ground, blue is car, purple is pedestrian, green is tree, yellow is street sign, red is building, grey is background class and white is unclassified (below probabilistic classification threshold). See our RSS 2009 paper for details and quantitative experiment results.


The scene, taken from left-, forward-, and right-facing cameras on the vehicle:


